In the last few weeks, two things happened that at first seemed incompatible:
1. Anthropic published a labour market report showing AI’s disruptive potential across knowledge work, with entry-level hiring slowing and entire occupational categories exposed. It’s easy to read that and think “AI is on the home stretch”.
2. Sequoia led a $1 billion seed round into Ineffable Intelligence, a pre-product, pre-revenue company founded by David Silver, the architect of AlphaGo and AlphaZero. His thesis? LLMs will never reach the next frontier because they only learn from what humans have already written down. In other words, they can only do things that humans can understand.
Personally, I’ve been using Claude to build things I don’t understand. Agents, data pipelines, workflows. I know enough to describe what I want and I can test the output. But I’m not an engineer by training, and so I’m trusting something I can’t fully explain.
How is it that while I can use LLMs to do things I can’t understand, Silver claims LLMs can only do what humans understand? And per the Anthropic report, is AI close to eating the world or have we barely started yet?
What does “understanding” actually mean?

2,400 years ago, Plato described prisoners in a cave watching shadows on the wall. They built entire theories about how shadows behave. The predictions worked. But they weren’t seeing the source itself, they were seeing a projection into the cave, dependent on multiple other variables (light, distance, the original objects). These shadows were caused by a world that existed behind them that they couldn’t see, a world beyond their own cave.
This is a useful analogy for human knowledge and understanding: we don’t truly “understand” the universe, we have models that we’ve tested and trust, but these models are sometimes built on “shadows” and dependent on truths we don’t yet understand. We can only trust models until they break.
Take Mercury. For centuries, Newton’s laws “explained” planetary motion to a high degree of accuracy. Then astronomers noticed Mercury’s orbit drifting by c.40 arc-seconds per century. To explain the aberration, they invented a planet called Vulcan, spent over 50 years looking for it, tweaked Newton’s gravity exponent, and proposed invisible dust clouds. But in essence all these attempted adjustments were trying to wedge a 3D object into a 2D shadow.
Then Einstein published general relativity and predicted the drift exactly, without any adjustments. Newton’s laws weren’t slightly wrong. They were a shadow of a deeper reality.
The pattern repeats everywhere from Ptolemy to Copernicus to Newton to Einstein. Each model was “right” until an edge case broke it. Each successor revealed the previous as a shadow of something deeper. Understanding has never meant seeing absolute reality, it means having a model that’s good enough for now.
What do LLMs “understand”?
Simplistically, LLMs are trained on language, maths, and code, i.e. the entire written output of human knowledge. And they’re extraordinary at recalling, synthesising, and generating across all of it. The genius of LLMs is their ability to generalise across knowledge work for the purpose of analysis, code generation, and tool execution etc.
But language, maths, and code are the “shadow” of human learning as opposed to learning itself. They are our “map” of the world as opposed to the “territory” (see the “Map is not the Territory”, Korzybski). This distinction matters because it defines where LLMs dominate and where they might hit a wall:
- Where the “shadow” IS the skill: Content, translation, code generation, mathematical computation. LLMs will be better than humans at these because they draw on all human knowledge simultaneously. There is no gap between the map and the territory. We see this show up in the Anthropic chart below, with LLM dominance in areas like legal, computer & math, finance, etc.
- Where the “shadow” may fall short: Physics, biology, chemistry. We’ve codified Newtonian mechanics, genomics, protein structures etc., but each codification is a shadow of something deeper we as humans don’t fully grasp. An LLM trained on physics textbooks can be brilliant at physics as we’ve codified it. But can it see beyond our “shadows” to a world that’s more fundamental than we even grasp, to point out where our frameworks are wrong, or generate new theories? While LLMs trained on the output of human knowledge are great at predicting what a human might do, this is very different from an AI that can perceive the world and learn from experience to infer things de novo.
The next-frontier: “Non-shadow models”
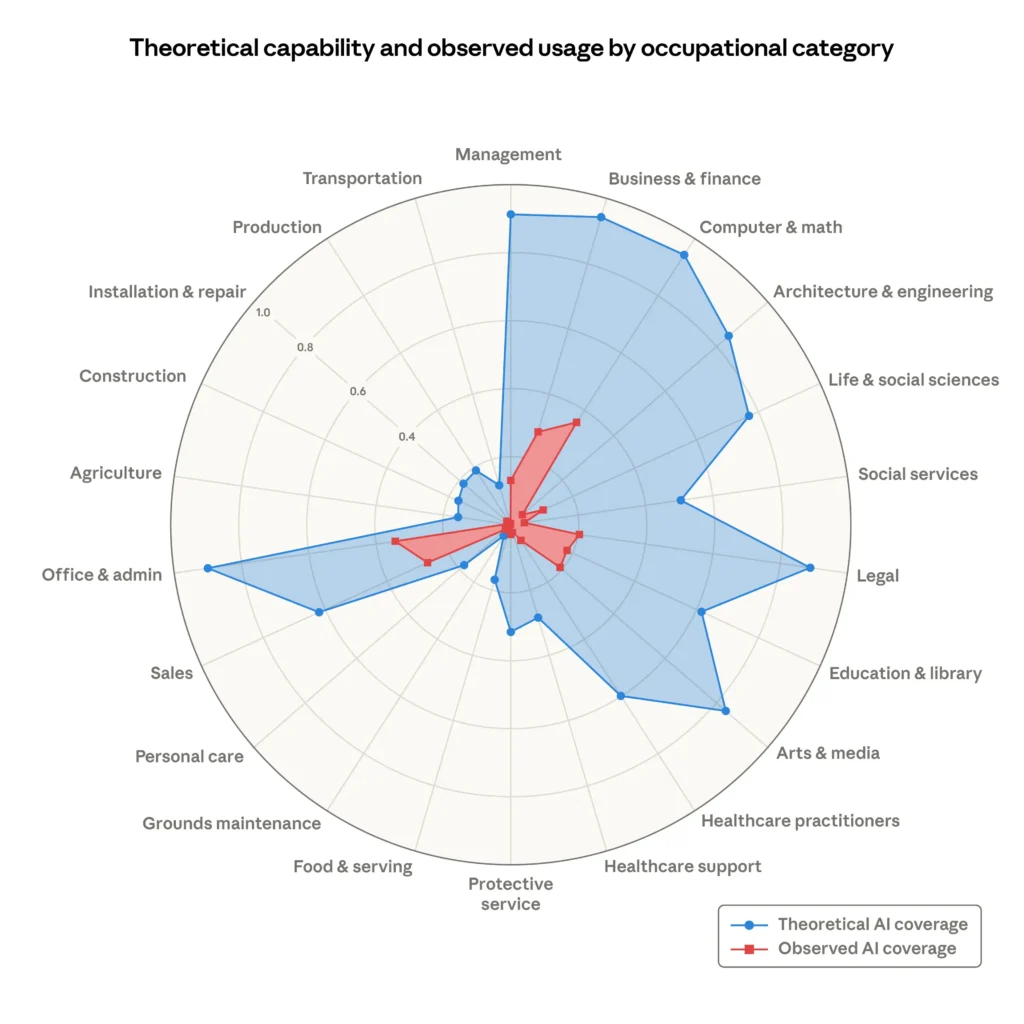
But the reason a $1b seed round still makes sense (let’s park the discussion on price for now) while Anthropic continues its march across these occupational categories, is that these are not the final frontier.
We should expect a new wave of opportunities in the future which are AI systems operating where human codification has been weakest: Physics, Biology, Chemistry, Materials science. In other words, the domains in which seeing beyond the shadows has the highest value.
The companies building here look different to LLMs. They’re training in simulations and physical environments. Their data is experimental results and sensor readings, not documents. They’re using Reinforcement Learning (‘RL’) and self-play. And critically, they’re in domains where being wrong about the “map” has massive consequences, and therefore massive upside for getting it right.
AlphaFold didn’t read biology papers and get better at answering questions (e.g. through next token prediction). It solved protein folding (a problem scientists worked on for 50 years) by finding patterns in structural data that no human had codified. To frame the impact of these approaches, DeepMind spun out Isomorphic Labs specifically to commercialise AlphaFold’s approach to drug discovery.
Within three years, they’d signed billions in milestone deals with leading pharma companies, raised $600m+ in funding, and Hassabis and Jumper had won the Nobel Prize. While we’re still in the early innings, this gives a sense of the commercial shape of “seeing beyond the shadows”, and unlocking problems previously unsolvable to humans.
At Frontline we’re excited by these new frontiers. Our portfolio company Stanhope AI has developed a proprietary ‘free energy minimizing’ world model for decision-making in scenarios with imperfect data. Their model attempts to mimic the human brain as its reasons in real-time dynamic environments, as opposed to predicting the next token based on the output of that reasoning.
Containing what we’ve discovered is less powerful than the ability to discover
Richard Sutton’s Bitter Lesson nails it: “We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovering process can be done.”
Chess engines with hand-coded opening books lost to AlphaZero, which learned from scratch. Go programs with human heuristics lost to AlphaGo, which discovered Move 37, a move that broke 3,000 years of accumulated human wisdom.
LLMs are the most sophisticated library ever built. They recombine everything humanity has written down in ways that are genuinely transformative. But the physicist in me is excited for future models that don’t work off the output of human knowledge as its starting point. Models that can build, test, and learn beyond even the dimensions and fidelity of our own human senses, experience, and knowledge. To uncover the world that’s casting the shadows we perceive.
To return to my opening question on what it means to “understand”: the future is not just us using models to build things we personally don’t understand. It’s models doing things no human has ever understood.
That’s why the Anthropic report and Sequoia investing in Silver aren’t incompatible, they’re two chapters of the same story. One is about how far AI goes with the map we’ve already drawn. The other is about what happens when it starts exploring the territory.